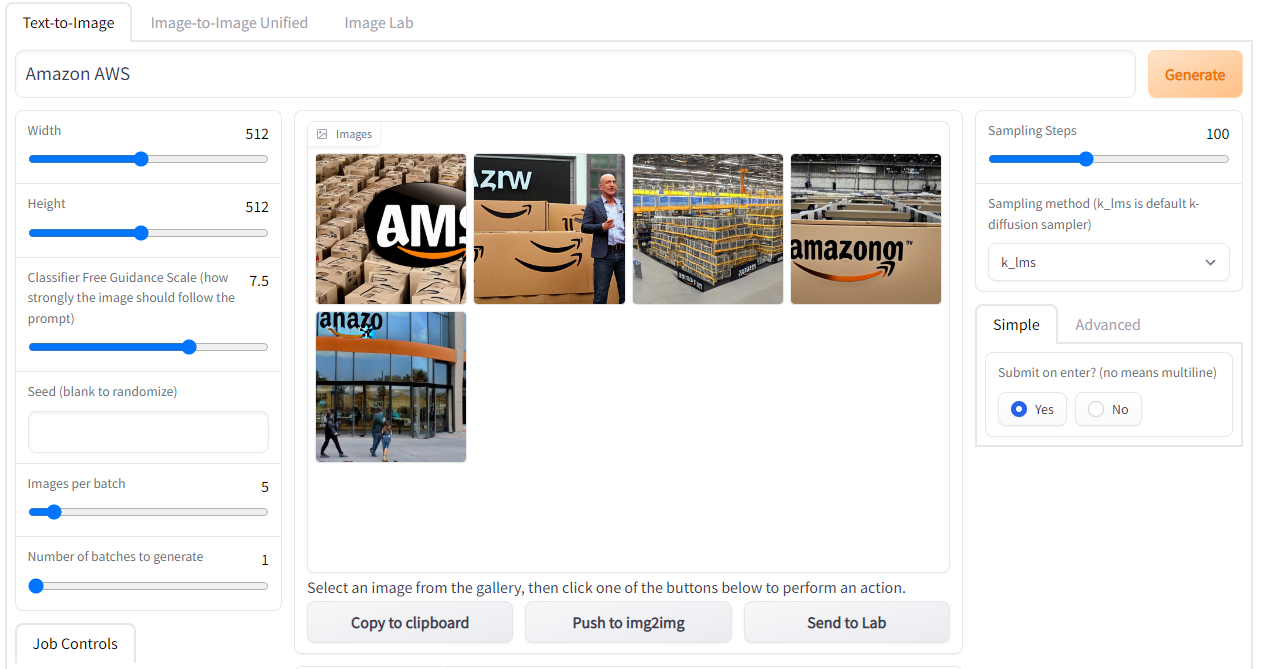
概要
最近話題のAI様に画像を生成して頂けるツール「Stable Diffusion」を軽い気持ちで導入してみました。せっかくなので手順を残しておきます。
全体の構成は、画像生成サーバ(AI様)をWindows上で稼働させ、人間はブラウザ(Chrome等)からアクセスし、テキストを献上して画像を生成して頂きます。
※「Stable Diffusion web UI」利用してブラウザから操作します。
<実行環境>
- OS:Windows11
- CPU:インテル Core i7 12700F
- GPU:GeForce RTX 3060Ti
<実行例>
- テキスト:「良い景色,日本」
※実行する度に結果は変わります。
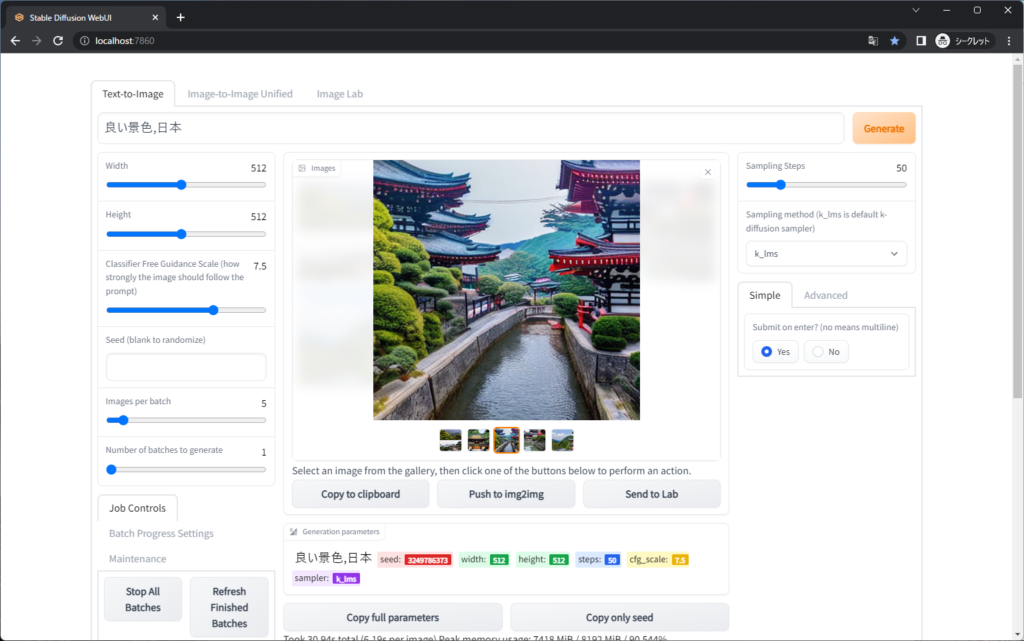
導入
以下を順番に導入します。
- モデルデータファイルのダウンロード(HuggingFace)
- Stable Diffusion web UIのダウンロード&構成変更(GitHub)
- Minicondaのダウンロード&インストール ※(導入済みの場合はスキップ)
- Gitのダウンロード&ユーザ設定 ※(導入済みの場合はスキップ)
- Stable Diffusion web UIのリポジトリ初期化
- Stable Diffusion web UIのインストール&実行
1.モデルデータファイルのダウンロード(HuggingFace)
HuggingFaceへアカウントを登録し、モデルデータファイルをダウンロードします。
1-1.HuggingFaceでアカウントを登録(初回のみ)
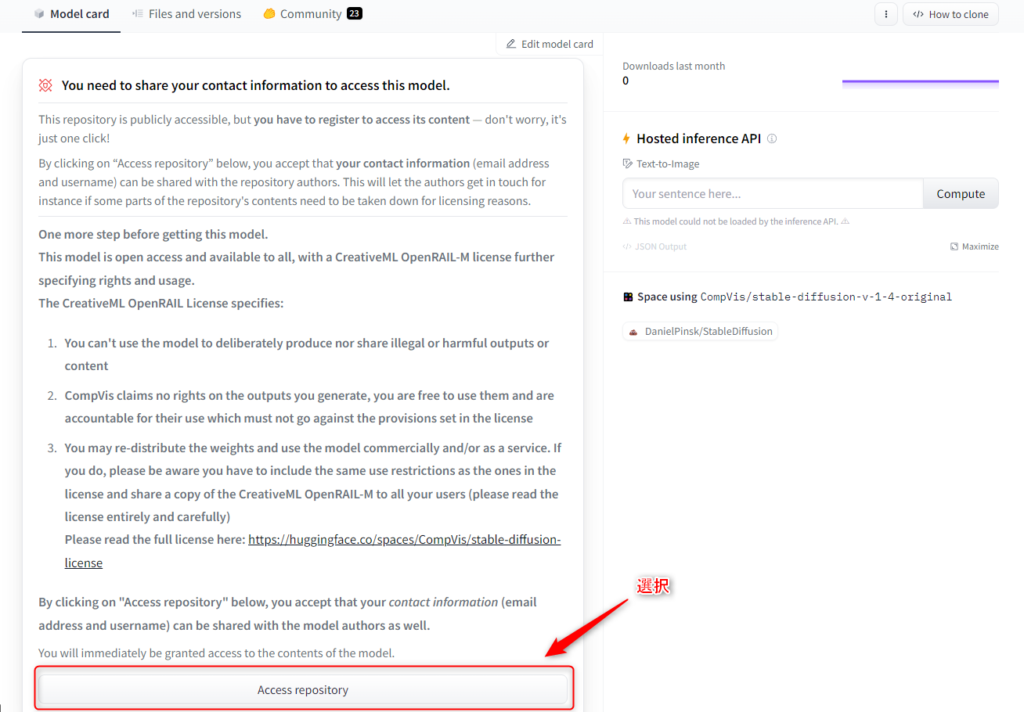
①下記サイト(HuggingFace)へアクセスして、「Access repository」を選択します。
<HuggingFace>

②「Sign Up」を選択して、アカウントを登録します。(適当なメールアドレスで大丈夫です。)
1-2.「sd-v1-4.ckpt」ファイルをダウンロード
①アカウント登録後、ログインします。
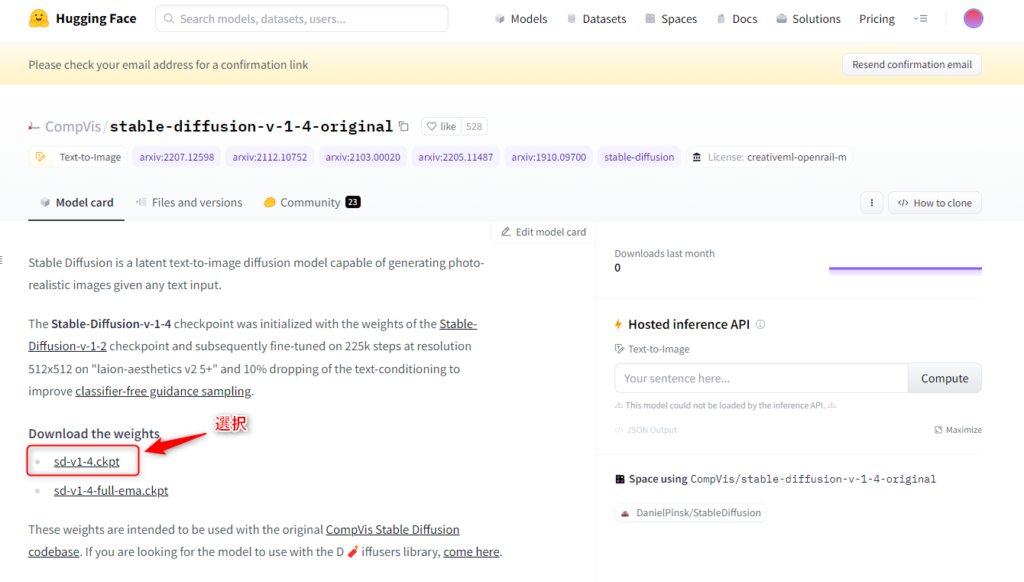
②「sd-v1-4.ckpt」を選択してファイルをダウンロードします。(約4GB)
2.Stable Diffusion web UIのダウンロード&構成変更(GitHub)
「Stable Diffusion web UI」のソースコードをダウンロードし、モデルデータファイルを配置するなど構成を変更します。
2-1.ソースコードのダウンロード
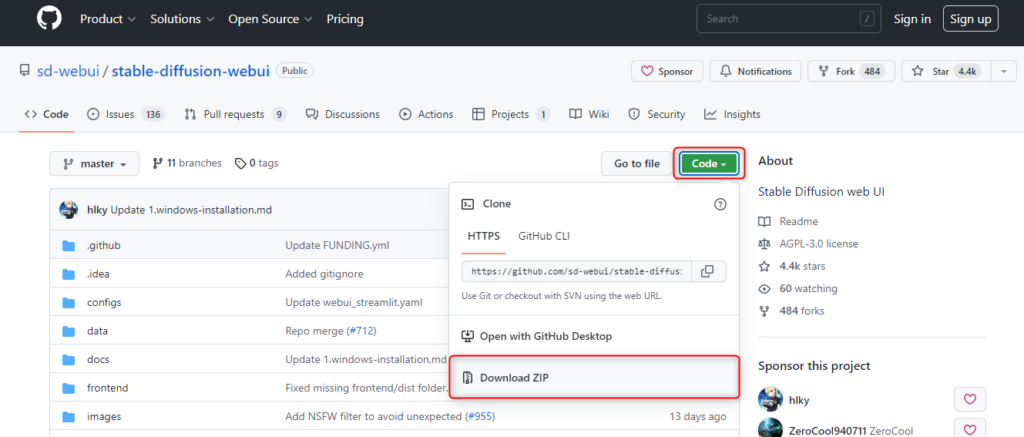
①下記サイト(GitHubリポジトリ)へアクセスし、「Code」>「Download ZIP」を選択してソースコードをダウンロードします。
<GitHubリポジトリ>
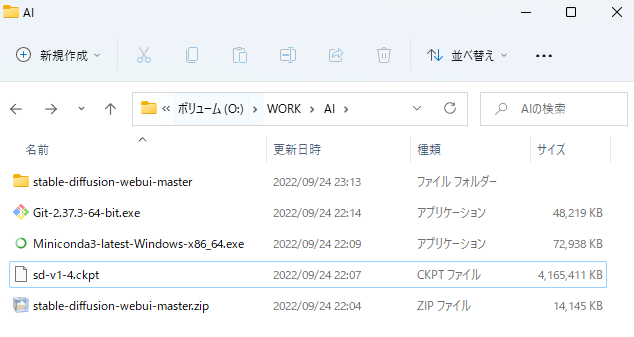
②ZIPファイルをダウンロード後、任意の場所へ解凍してください。
※「stable-diffusion-webui-master」ディレクトリが配置されていればOK!
2-2.モデルデータファイルを配置
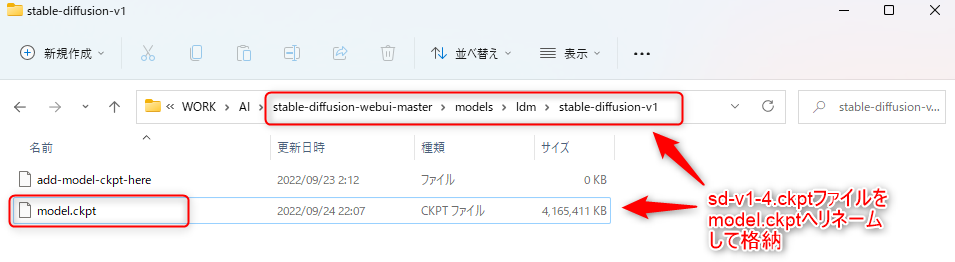
①「sd-v1-4.ckpt」のファイル名を「model.ckpt」に変更して、「任意のディレクトリ\stable-diffusion-webui-master\models\ldm\stable-diffusion-v1\」配下へ格納します。
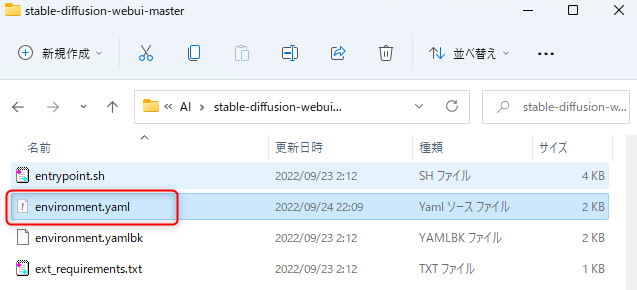
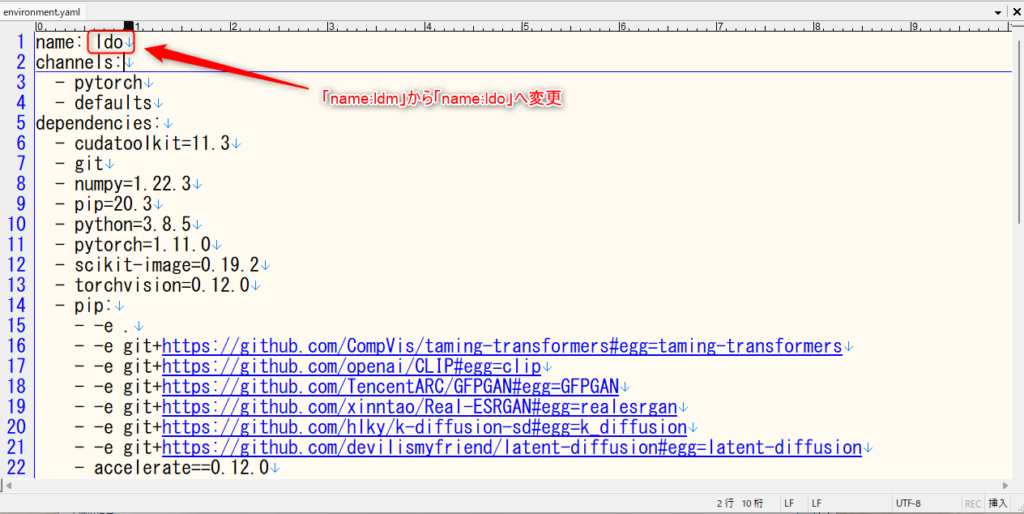
②最後に「任意のディレクトリ\stable-diffusion-webui-master\」に配置されている「environment.yaml」をメモ帳等で開き、1行目の「name:ldm」を「name:ldo」へ変更して保存します。
3.Minicondaのダウンロード&インストール
「Stable Diffusion web UI」の動作に必要なMinicondaをダウンロード&インストールします。
※導入済みの場合はスキップ
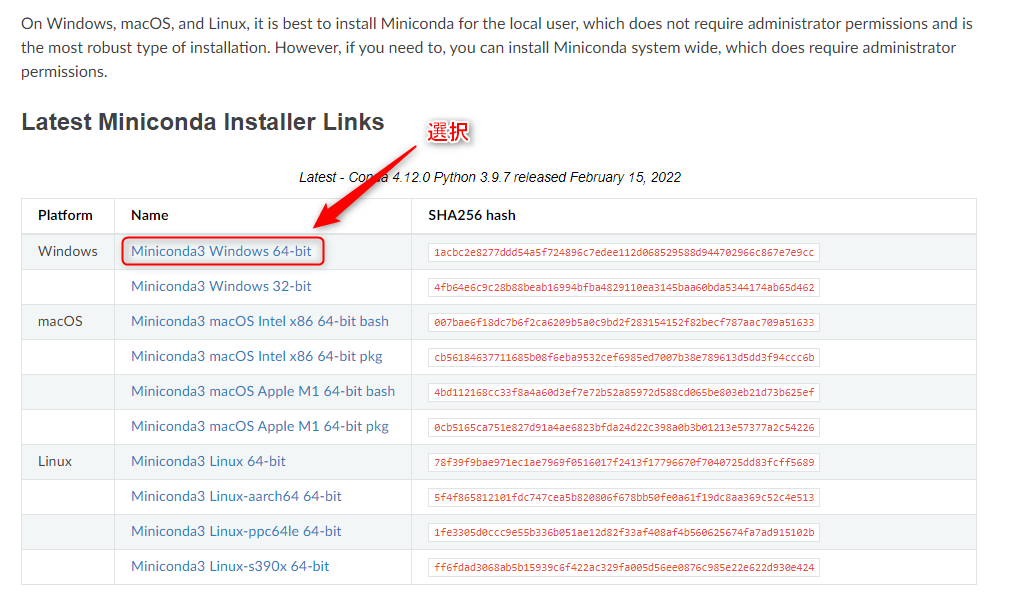
3-1.Minicondaのダウンロード
①下記サイトからWindows用のインストーラをダウンロードします。
<Miniconda>

3-2.Minicondaのインストール
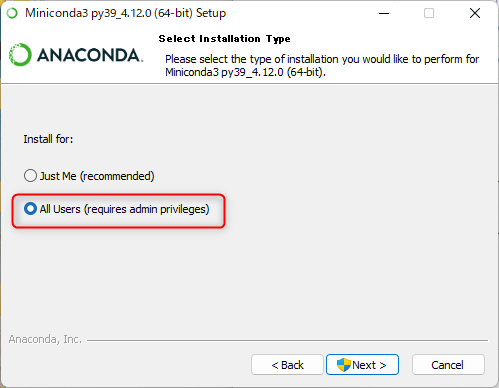
①ダウンロードしたインストーラーを起動して「Next>」>「I Agree」と遷移し、下記画面で「All Users」を選択して「Next>」を押下します。
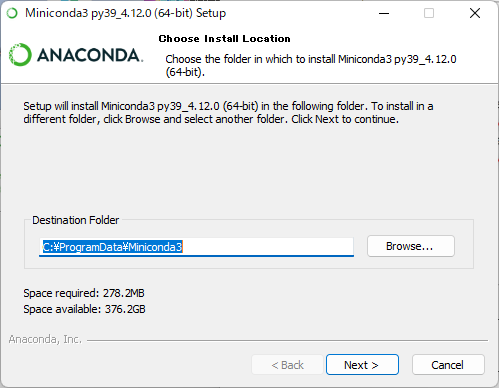
②任意のダウンロード先を設定して、「Next>」を押下します。
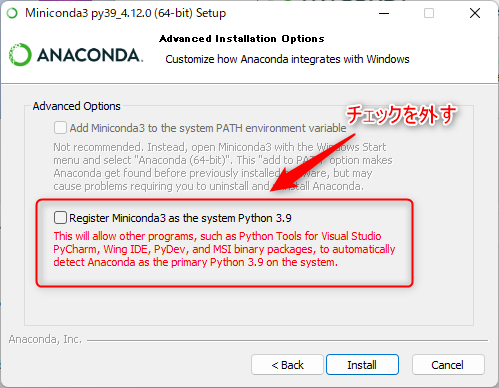
③「Register Miniconda3 as the system Python 3.9」のチェックを外して「Install」を押下します。
4.Gitのダウンロード&インストール&ユーザ設定
Gitをダウンロード&インストールして、ユーザ設定を実施します。
※導入済みの場合はスキップ
4-1.Gitのダウンロード
①下記サイトからWindows用のインストーラをダウンロードします。
<Git for Windows>


4-2.Gitのインストール
①基本的にデフォルト設定のまま「Next」を押下で画面を遷移し、下記画面では「Git from the command line and also from 3rd-party software」を選択します。
※Gitをコマンドラインから利用可能とする設定です。
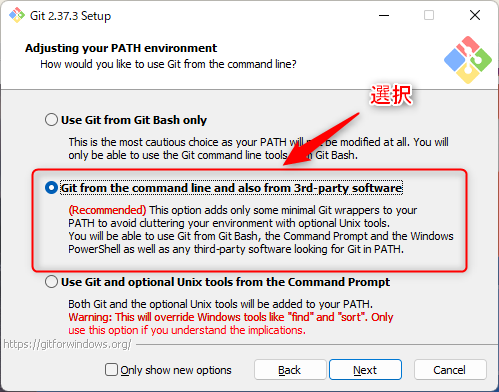
②後はお好みで項目を選択し(デフォルト可)、最後の画面で「Install」を押下します。
4-3.ユーザ設定
①コマンドライン(cmd)から以下のコマンドを実行して、Gitを利用するユーザ情報を設定します。
$ git config --global user.name "任意のユーザ名"
$ git config --global user.email "任意のメールアドレス"

5.Stable Diffusion web UIのリポジトリ初期化
①コマンドプロンプトを開き、カレントディレクトリを「任意のディレクトリ\stable-diffusion-webui-master\」へ移動して、下記コマンドを実行します。
$ git init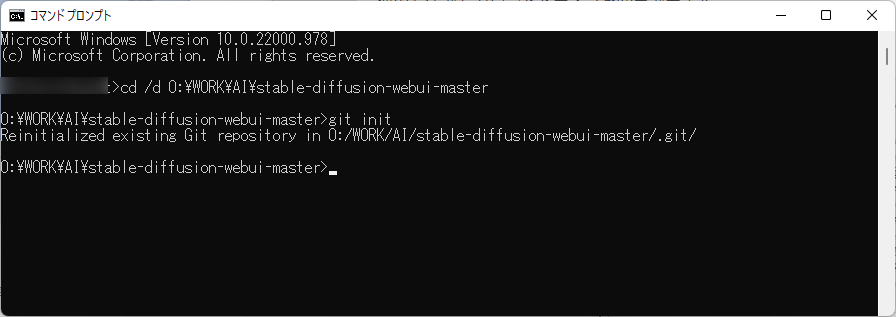
6.Stable Diffusion web UIのインストール&実行
①「任意のディレクトリ\stable-diffusion-webui-master\」に配置されている「webui.cmd」をダブルクリックで実行します。
②入力欄に「Y」と入力しEnterキーを押下します。
※初回は様々なパッケージのダウンロードとインストールが実行されるため、完了までしばらくお待ちください。
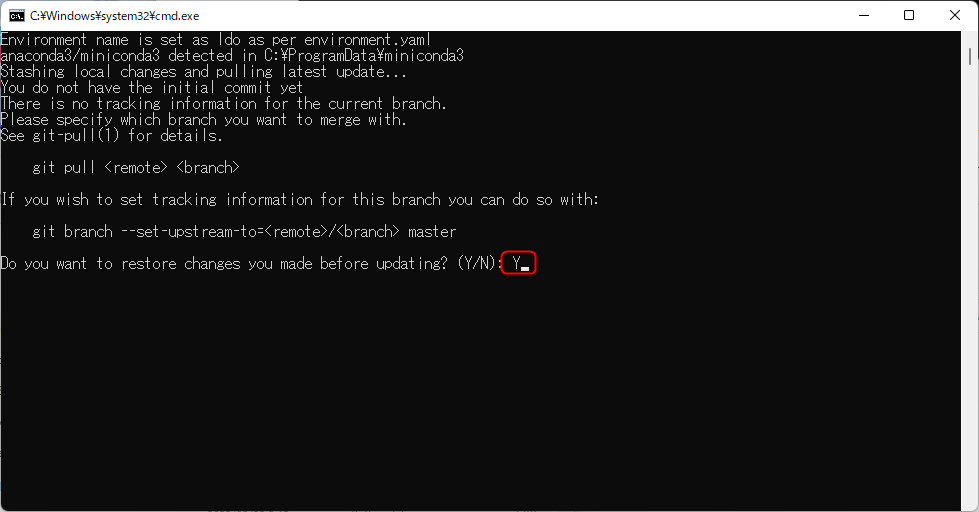
※下記の様なメッセージが出力された場合は、何でも良いのでキーを押下してください。

③下記「http://localhost:7860/」の様にURLが出力されたら実行開始です。
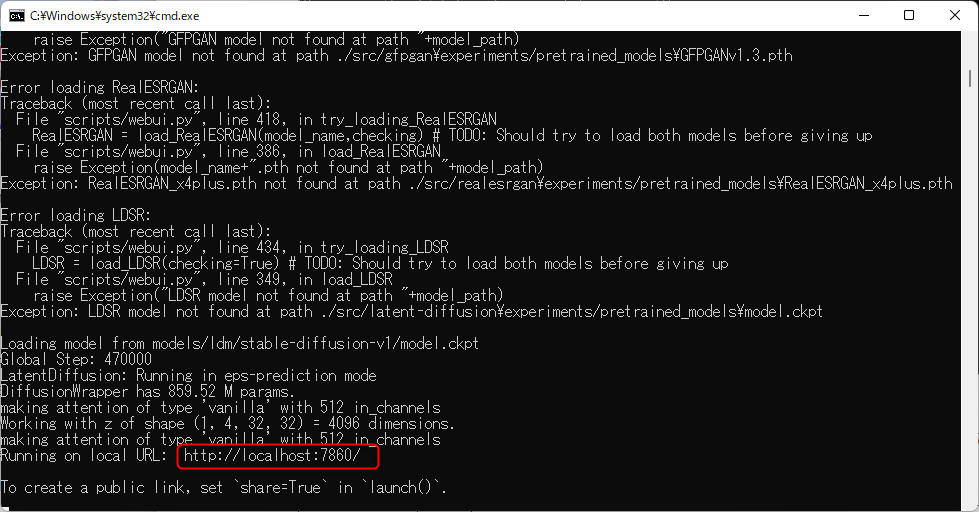
④Chrome等のブラウザから「http://localhost:7860/」へアクセスし、「Stable Diffusion web UI」へアクセスします。
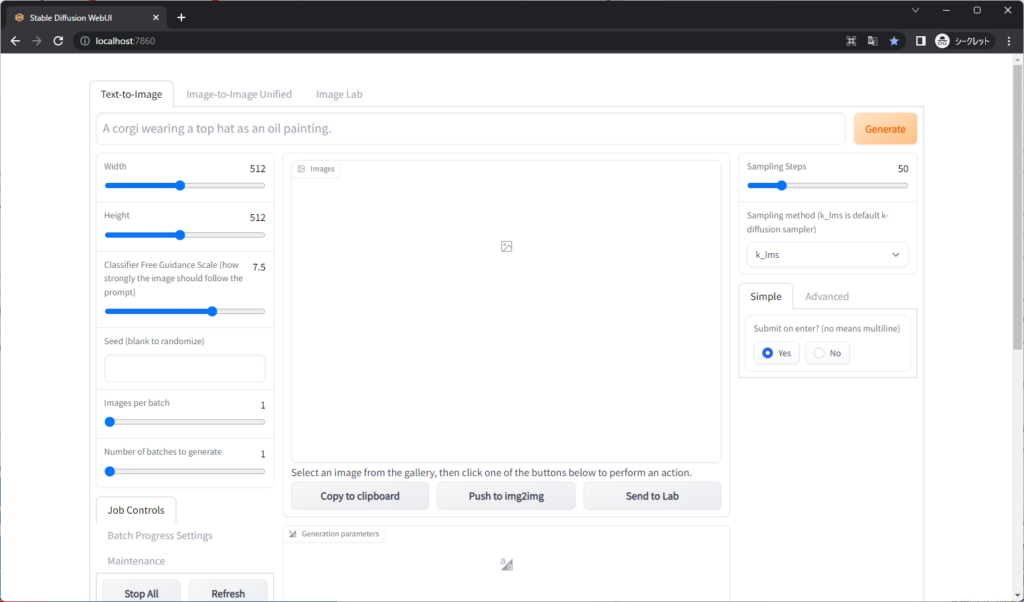
Stable Diffusion web UIの簡単な使い方
テキストを入力して画像を生成
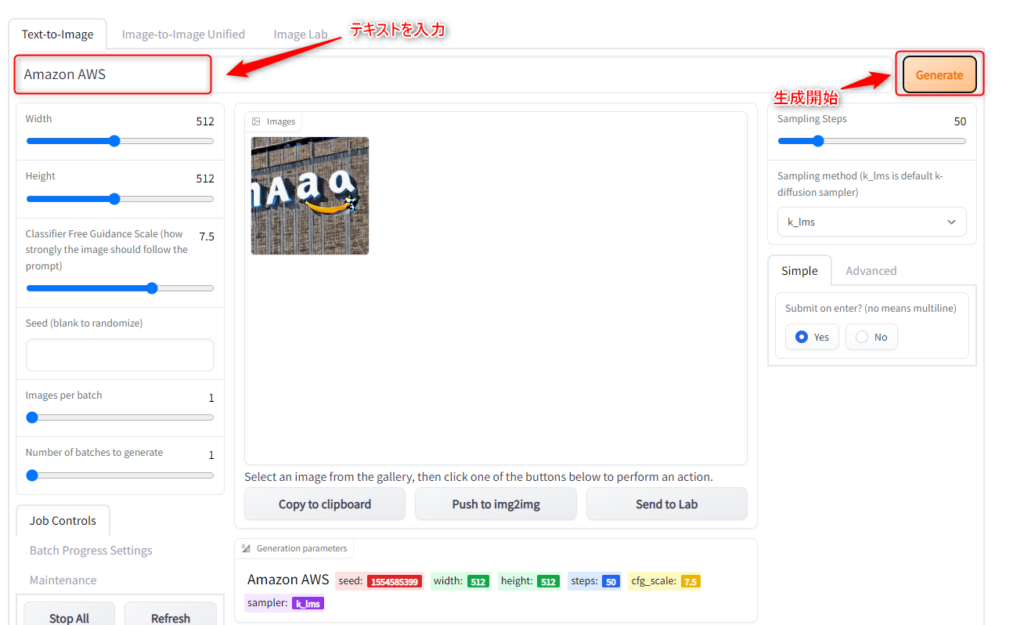
・【Text-to-Image】タブの「Generate」ボタン左に位置するテキストボックスへテキストを入力し、「Generateボタン」を押下します。
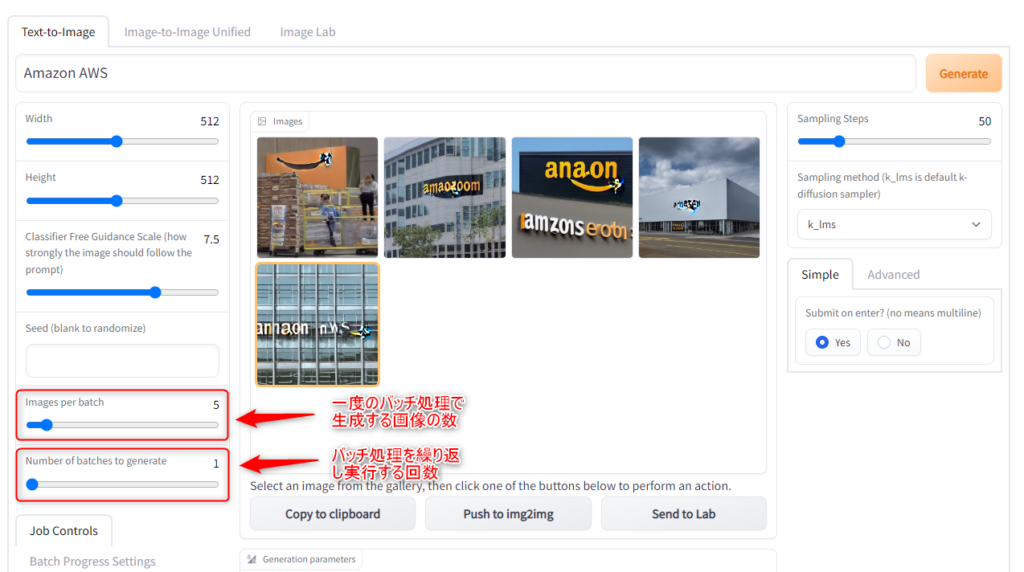
一度に生成する画像の数を増やす
・【Text-to-Image】タブの「Images per batch」の数値を変更する事で、一度の実行で生成する画像の数を増減させる事が出来ます。
・【Text-to-Image】タブの「Number of batches to generate」の数値を変更する事で、一度の実行で実行するバッチ処理の回数を増減させる事が出来ます。
※「Images per batch」×「Number of batches to generate」=一度の実行で生成する画像の総数
→「Images per batch」を増やす程負荷が増加するため、「Number of batches to generate」でバッチ処理回数を分割する事が可能となっているのだと推測します。
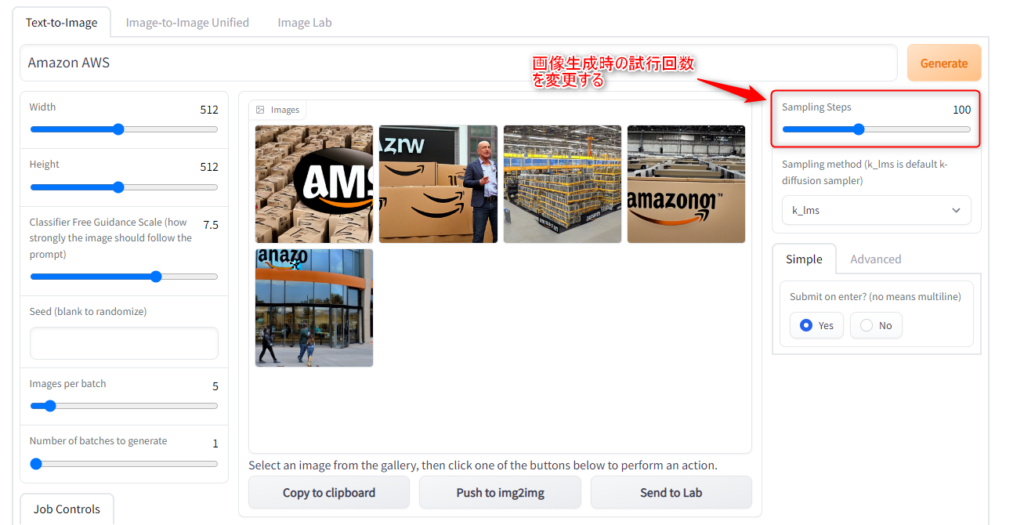
生成する画像の試行回数を変更する(精度を上げる)
・【Text-to-Image】タブの「Sampling Steps」の数値を変更する事で、一枚の画像を生成する際の試行回数(お題に対する反復回数)を増減させる事が可能です。
数値を増やす事で生成される画像の精度が上がるようです。
※数値を増やす程負荷が増加します。また、一概に増やせば良いというものでも無いようです。
あとがき
登場したばかりのサービスで、頻繁に更新されているようなので、手順はまた変更となりそうです。この記事執筆時(2022/09/25)では上記手順で導入する事が出来ました。
今回「Stable Diffusion」を使ってみて、AIを使ったサービスがいよいよ身近になってきたなぁと感じました。
今後どんな技術が世の中に出回るようになるのか、今から楽しみですね。((o(*゚ω゚*)o))
コメント