概要
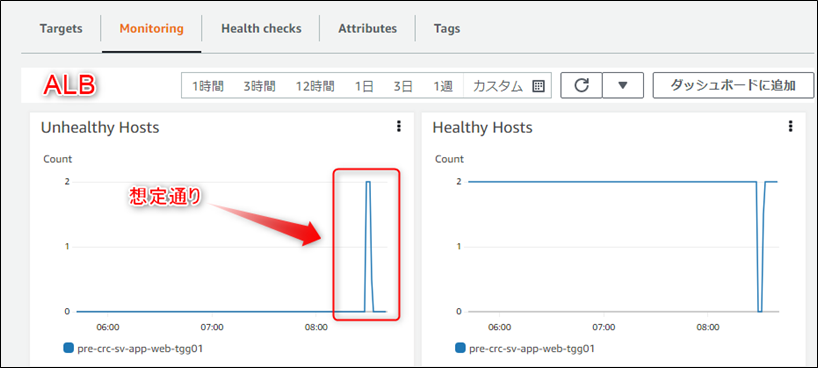
先日、下記のような構成のシステムに対して監視システムを構築しました。
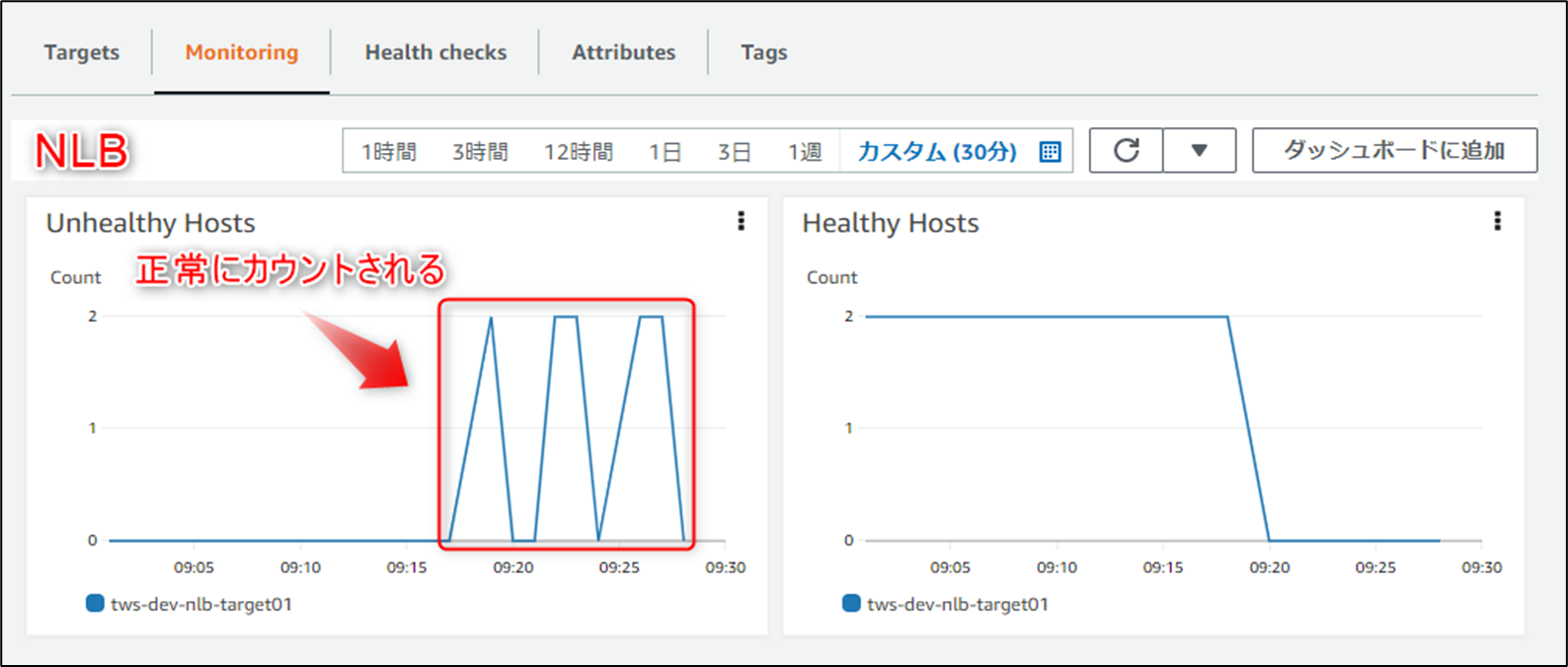
NLBターゲットグループのメトリクス「Unhealthy Hosts」(異常なインスタンスの数)がカウントされた際に発砲するアラートを実装してテストを行っていたところ、↓の<NLBターゲットグループのメトリクス>のように「Unhealthy Hosts」がカウントされず欠けてしまう現象が発生しました。
同テスト時にNLBのフロントに配置されているALBターゲットグループでは、<ALBターゲットグループのメトリクス>のように「Unhealthy Hosts」が正常にカウントされていたため、不思議に思いハマってしまったので、調査結果を記載します。
<システム構成>
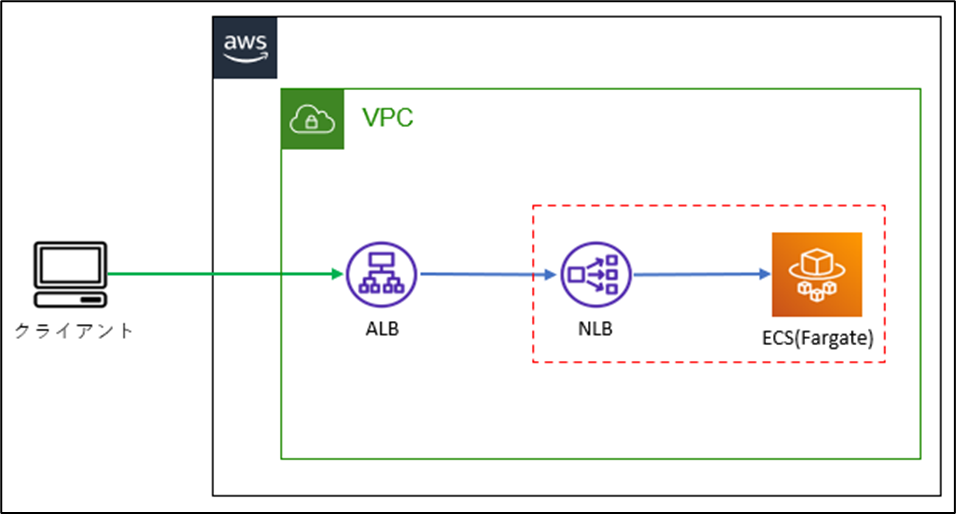
<NLBターゲットグループのメトリクス>
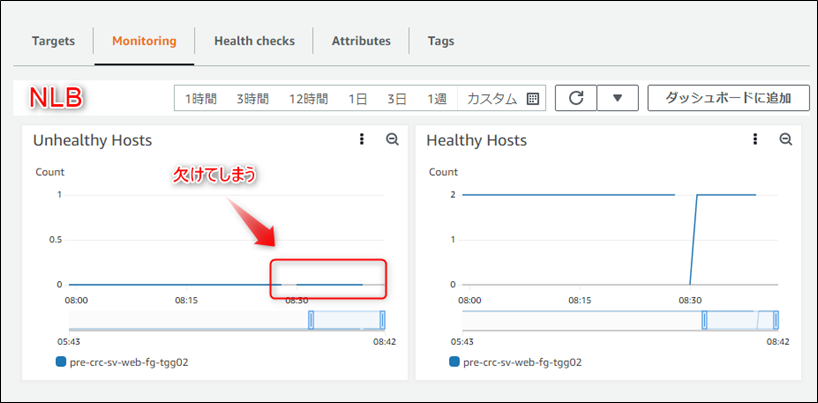
<ALBターゲットグループのメトリクス>
原因
結論として、NLBターゲットグループの「Unhealthy Hosts」はターゲットグループに設定されたヘルスチェックに規定回数失敗した際にカウントされるようです。(規定回数=設定している回数)
テスト実施時は、ECSのタスクを手動で停止させて異常なインスタンスを発生させていたため、停止されたタスクはNLBからただちに切り離されて、メトリクスの対象から外れてしまい「Unhealthy Hosts」が欠けるような現象が発生しました。
また、ターゲットグループには「Deregistration delay」(登録解除の遅延=draining)の設定が存在するため、タスクが停止されてもメトリクスが急に欠けるような現象は発生しないのでは?と当初は考えていましたが、「Deregistration delay」は登録解除するターゲットへの新たなリクエストの送信を停止するものであるため、ヘルスチェックも新たに送信されなくなり結果として「Unhealthy Hosts」のメトリクスが欠ける状況に繋がったと判断しました。
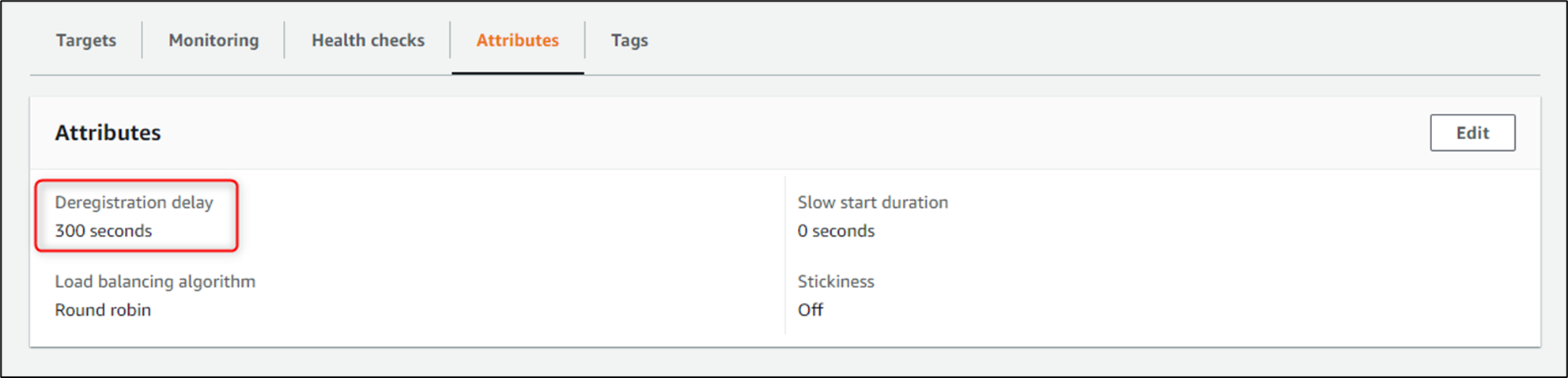
登録解除の遅延
Elastic Load Balancing は、登録解除するターゲットへのリクエストの送信を停止します。デフォルトでは、Elastic Load Balancing 登録解除プロセスを完了する前に 300 秒待って、ターゲットへ処理中のリクエストが完了するのを助けることができます。
<登録解除の遅延のリファレンス>
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/load-balancer-target-groups.html#deregistration-delay
解決策
テストはNLBターゲットグループのヘルスチェックに失敗する構成に変更して実施しましょう。(単純)
ECS側のセキュリティグループをNLBからのヘルスチェックが疎通しないように変更してしまう方法が手っ取り早いと思います。
上記を実施すると以下のように「Unhealthy Hosts」は正常にカウントされました。ヾ(≧∇≦*)/やったー
<NLBターゲットグループのメトリクス>
あとがき
監視対象のシステムは別のチームがCFnで構築しており、環境に手を加えるとドリフトが発生してしまうため、テスト時にネットワーク設定を変更してヘルスチェックを失敗させるなどの確認が出来ない状況でした。最終的には別の環境作って確認したのですが調査に時間が掛かってしまいました。(-_-;)
NLBはALBと違ってただのNW機器のようなイメージなので、ECSタスクの切り離しやメトリクス取得の仕様に差異が存在するようです。
コメント