概要
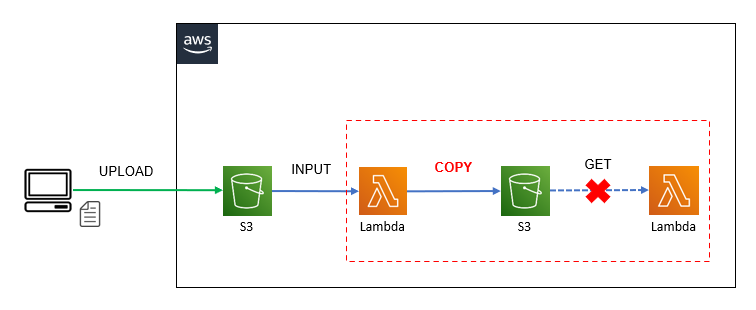
以下の構成図のようにS3にアップロードされたファイルをそのまま別バケットへ再配置して、後続の処理へ連携したいケースで、copy機能を利用して再配置してしまうと後続の処理で”NoSuchKey: An error occurred (NoSuchKey)”(ファイルが存在しませんエラー)が発生する事があります。
※以下の構成図では2つ目のLambdaでファイルの取得に失敗しています。
<構成図(copy機能利用)>
<エラー>
NoSuchKey: An error occurred (NoSuchKey) when calling the GetObject operation: The specified key does not exist.原因
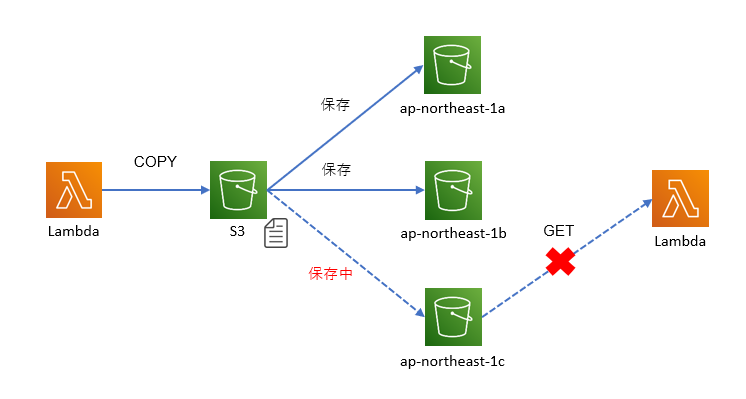
copy機能を利用してファイルを再配置するとS3の結果整合性によるファイル配置が適用されるため、コンソール上ではファイルが存在しているように見えても、内部的にファイルの配置が完了していない状況が発生する事があります。
S3の結果整合性とは
ファイルを配置すると、自動的に同じリージョンの各AZへファイルのレプリケーションを開始します。
対象のファイルサイズが小さい場合は、後続の処理が開始する前に各AZへのレプリケーションが完了している事がほとんどですが、1GBを超えるようなファイルをcopyしていると後続の処理が開始するまでにAZ間のコピーが完了していない状況が発生する事があります。
<イメージ>
解決策
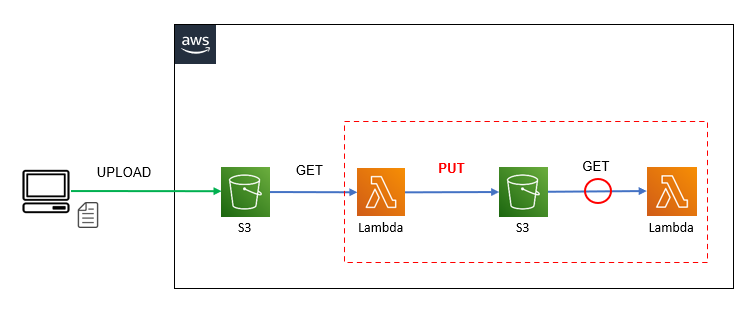
以下の公式ドキュメントに記載されている通り、put機能を利用してファイルを再配置する事でS3の強い一貫性によるファイル配置が適用されるため、後続の処理開始時にファイル配置が完了している事が保証されるようになりエラーが発生しなくなります。(2020年12月1日のアップデートから)
<公式ドキュメント>

<構成図(put機能利用)>
サンプルコード(Python + boto3)
copy機能を利用したコード
S3の結果整合性が適用されます。
import boto3
import json
import datetime
import urllib.parse
from botocore.exceptions import ClientError
def lambda_handler(event, context):
print('s3 copy start')
s3 = boto3.client('s3')
# input file
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
file_name = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8').split('/')[-1]
copy_source = {'Bucket': input_bucket, 'Key': input_key}
# output file
d_today = datetime.date.today()
output_bucket = 'your output bucket name'
output_key = 'zzzzz/' + str(d_today) + '-' + file_name
print('outputfile:' + output_key)
# copy
try:
s3.copy_object(CopySource=copy_source, Bucket=output_bucket, Key=output_key)
except ClientError as e:
print(e)
return False
print('Finish function!')
return True
if __name__ == '__main__':
data = '''
{
"Records": [
{
"s3": {
"bucket": {
"name": "your input bucket name"
},
"object": {
"key": "your file key"
}
}
}
]
}
'''
event = json.loads(data)
context = None
lambda_handler(event, context)put機能を利用したコード
S3の強い一貫性が適用されます。
※インプットファイルをダウンロードして、アウトプット先のバケットへputします。
import json
import boto3
import datetime
import urllib.parse
from botocore.exceptions import ClientError
def lambda_handler(event, context):
print('s3 output start')
s3_resource = boto3.resource('s3')
# input file
bucket_name = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
file_name = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8').split('/')[-1]
# download input file
input_bucket = s3_resource.Bucket(bucket_name)
file_path = '/tmp/' + file_name
try:
print('Downloading s3 file...')
input_bucket.download_file(input_key, file_path)
# upload input file
d_today = datetime.date.today()
output_bucket = s3_resource.Bucket('your output bucket name')
output_key = 'zzzzz/' + str(d_today) + '-' + file_name
print('outputfile:' + output_key)
print('Uploading s3 file...')
output_bucket.upload_file(file_path, output_key)
except ClientError as e:
print(e)
return False
print('Finish function!')
return True
if __name__ == '__main__':
data = '''
{
"Records": [
{
"s3": {
"bucket": {
"name": "your input bucket name"
},
"object": {
"key": "your file key"
}
}
}
]
}
'''
event = json.loads(data)
context = None
lambda_handler(event, context)ファイルを一時領域にダウンロードするため、Lambdaの「エフェメラルストレージ」をデフォルトの512MBから拡張しておく必要があります。(想定されるファイルサイズの上限)
後続の処理
再配置されたファイルのダウンロードと1行目のデータを出力します。
import boto3
import json
import urllib.parse
from botocore.exceptions import ClientError
def lambda_handler(event, context):
print('s3 output start')
# s3_client = boto3.client('s3')
s3_resource = boto3.resource('s3')
# input file
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
file_name = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8').split('/')[-1]
# download output file
bucket = s3_resource.Bucket(input_bucket)
file_path = '/tmp/' + file_name
try:
print('Downloading s3 file...')
bucket.download_file(input_key, file_path)
# 1行目だけ読み込んで出力
print('Disp row...')
with open(file_path, mode='r', encoding="utf_8_sig") as f:
s_line = f.readline()
print(s_line)
except ClientError as e:
print(e)
return False
print('Finish function!')
return True
if __name__ == '__main__':
data = '''
{
"Records": [
{
"s3": {
"bucket": {
"name": "your input bucket name"
},
"object": {
"key": "your file key"
}
}
}
]
}
'''
event = json.loads(data)
context = None
lambda_handler(event, context)まとめ
当現象に悩まされていた時期は2021年の春ごろですが、現在(もしくは今後)は解消されている可能性があります。
※試しに上記コードで1GBのファイルをcopyしてみましたが、エラーは発生しませんでした。(たまたま?)
当時はS3とLambdaの間にSQSを配置して、キューの配信を数分遅延させて解消を図ったりもしてみましたが、同じエラーが発生してしまいSQS連携では解消できませんでした。
また、Lambda内でエラーハンドリングして一定時間スリープした後にファイルのGETを再実行しても何故かファイルが取得できず、またもや同じエラーが発生しました。(Lmabda本体の再試行でも同様)
最終的にはLambdaとEFSを連携させ、EFS内へファイルを一時的にダウンロードしてからputを実行後し、ダウンロードしたファイルを後処理で削除するといった対応を行いました。
今回検証を行う中で初めて気づいたのですが、Lambdaのエフェメラルストレージが拡張可能となっていたため、EFSの連携とダウンロードファイルの削除といった後始末が不要となり、とても簡単に作成する事ができました。(神アプデ!)


コメント